So occasionally, with varying time from several hours to several days I’ll notice the sensors haven’t updated and the UI shows Max_Age_Exceeded. Hitting the settings gear and Restart Backend brings them back to life. Is there any way to automate this procedure?
There should never be a reason to restart the backend. If there’s an issue with a controller, we should find the problem and try to fix it. At the very least, restarting just a single controller is preferred over the entire daemon (which restarts every controller). This can be accomplished with the Activate and Deactivate Controller Actions.
They’re i2c Scientific Atlantic so they are both typically stopped. I just restarted the backend again but by tomorrow I may be able to try deactivate/activate the pH and temp sensors and see what happens.
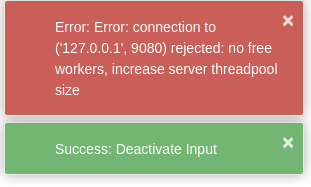
Alright, sensors failed an hour ago. Been sitting here waiting for the nice slow refreshes on the Pi. Got into Input but couldn’t deactivate. The “Success: Deactivate Input” didn’t actually deactivate so I just restarted the backend like I normally do. FWIW, this setup was a fresh headless install on the latest Raspberry Pi OS using a high endurance microSD. Pi 3 B, 1GB RAM. Been a couple months of use so far.
Without errors, it’s impossible to diagnose the issue. Check the Daemon Log for any relevant log lines. I have several Atlas Scientific devices (I believe that’s what you meant by “Scientific Atlantic”), and there are many currently in use with Mycodo, and none cause crashes, so there is likely something wrong with your particular system.
Lol. Yeah, Atlas Scientific. So deactivating did apparently work but it didn’t show. I rebooted and had to Activate. Are the logs accessible in /var/logs so I don’t have to try through the browser?
This just spewed in the terminal as I was looking at the log, not sure if it is relevant yet:
Traceback (most recent call last):
File "/var/mycodo-root/env/lib/python3.9/site-packages/Pyro5/socketutil.py", line 132, in receive_data
chunk = sock.recv(size, socket.MSG_WAITALL)
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/var/mycodo-root/mycodo/controllers/base_controller.py", line 81, in run
self.loop()
File "/var/mycodo-root/mycodo/controllers/controller_input.py", line 236, in loop
message = self.control.trigger_action(
File "/var/mycodo-root/mycodo/mycodo_client.py", line 158, in trigger_action
You’re not showing the entire traceback, you left out the most important part, the error near the bottom. Always include the entire traceback. Also, you need to be looking for the relevant log lines that occur when the issue occurs, not simply random errors you come across. Yes, the logs are in /var/log/.
Yeah, just figured I’d toss that in there since I was it threw itself up while I was looking at the logs. Now that I know the logs are in the normal location I’ll find the error when it happens again. I apologize for being scatter brained. It isn’t easy raising a special needs kid.
I think I may have fixed the issue. Seems the voltage regulator powering the Pi may have been at fault. Current uptime is 8 days without any hiccups.
1 Like